Beginner's Guide: Run DeepSeek R1 Locally

DeepSeek R1 brings state-of-the-art AI capabilities to your local machine. With optimized versions available for different hardware configurations, you can run this powerful model directly on your laptop or desktop computer. This guide will show you how to run open-source AI models like DeepSeek, Llama, or Mistral locally on your computer, regardless of your background.
Why use an optimized version?
- Efficient performance on standard hardware
- Faster download and initialization
- Optimized storage requirements
- Maintains most of the original model's capabilities
Quick Steps at a Glance
- Download Jan (opens in a new tab)
- Select a model version suited to your hardware
- Configure optimal settings
- Set up the prompt template & begin interacting
Let's walk through each step with detailed instructions.
Step 1: Download Jan
Jan (opens in a new tab) is an open-source application that enables you to run AI models locally. It's available for Windows, Mac, and Linux, with a streamlined setup process.
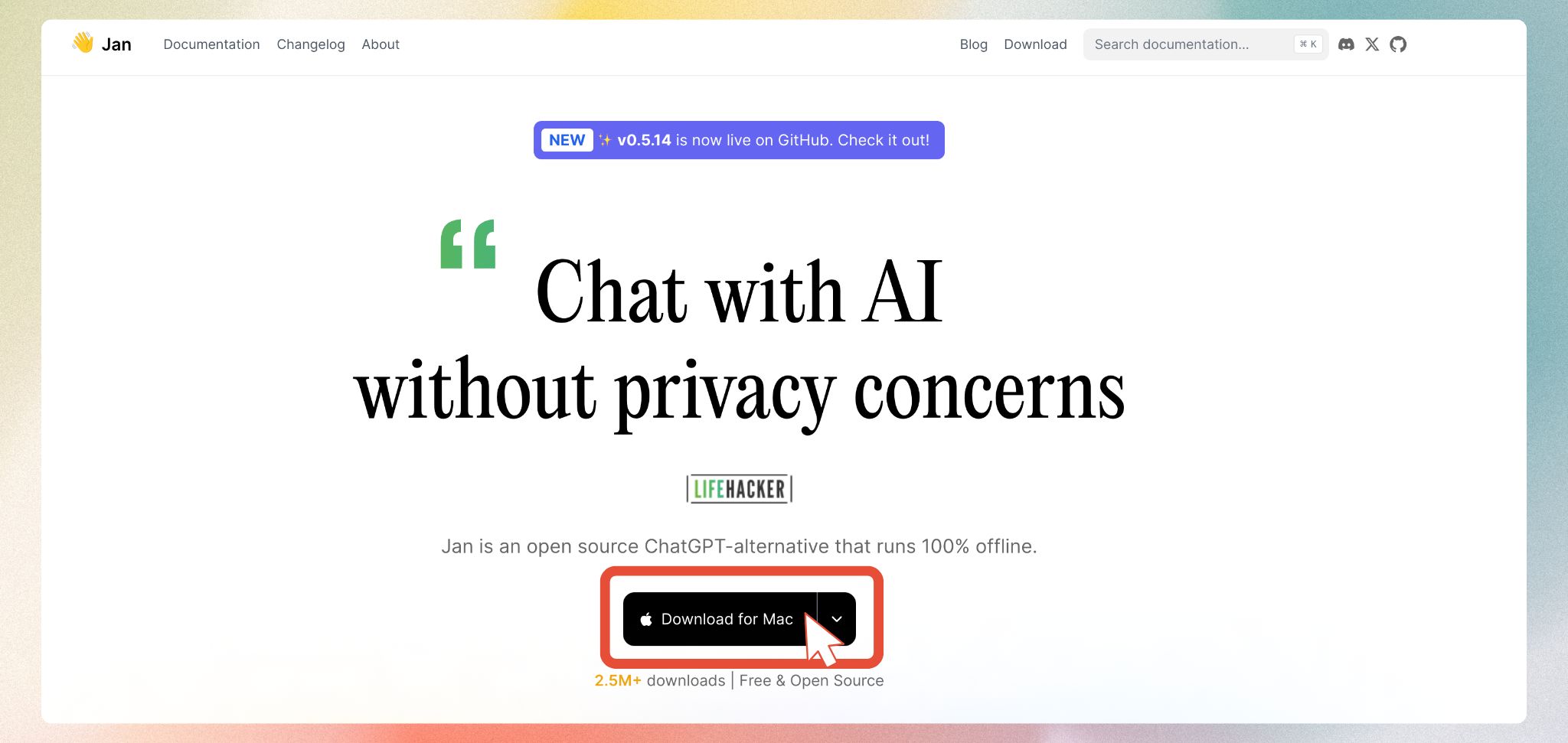
- Visit jan.ai (opens in a new tab)
- Download the appropriate version for your operating system
- Follow the standard installation process
Step 2: Choose Your DeepSeek R1 Version
DeepSeek R1 is available in different architectures and sizes. Here's how to select the right version for your system.
To check your system's VRAM:
- Windows: Press Windows + R, type "dxdiag", press Enter, click "Display" tab
- Mac: Apple menu > About This Mac > More Info > Graphics/Displays
- Linux: Open Terminal, run
nvidia-smi(NVIDIA GPUs) orlspci -v | grep -i vga
Understanding the versions:
- Qwen architecture: Optimized for efficiency while maintaining high performance
- Llama architecture: Known for robust performance and reliability
- Original vs Distilled: Distilled versions are optimized models that preserve core capabilities while reducing resource requirements
| Version | Model Link | Required VRAM |
|---|---|---|
| Qwen 1.5B | DeepSeek-R1-Distill-Qwen-1.5B-GGUF (opens in a new tab) | 6GB+ |
| Qwen 7B | DeepSeek-R1-Distill-Qwen-7B-GGUF (opens in a new tab) | 8GB+ |
| Llama 8B | DeepSeek-R1-Distill-Llama-8B-GGUF (opens in a new tab) | 8GB+ |
| Qwen 14B | DeepSeek-R1-Distill-Qwen-14B-GGUF (opens in a new tab) | 16GB+ |
| Qwen 32B | DeepSeek-R1-Distill-Qwen-32B-GGUF (opens in a new tab) | 16GB+ |
| Llama 70B | DeepSeek-R1-Distill-Llama-70B-GGUF (opens in a new tab) | 48GB+ |
Recommendations based on your hardware:
- 6GB VRAM: The 1.5B version offers efficient performance
- 8GB VRAM: 7B or 8B versions provide a balanced experience
- 16GB+ VRAM: Access to larger models for enhanced capabilities
To download your chosen model:
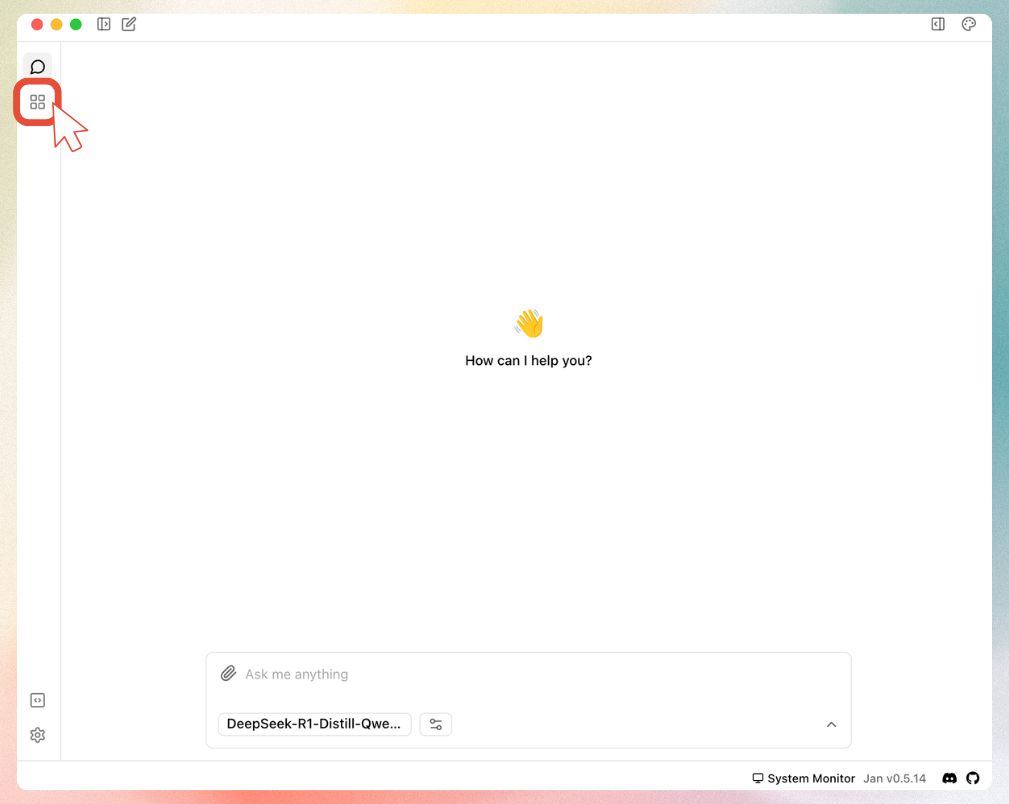
- Launch Jan and navigate to Jan Hub using the sidebar
- Locate the "Add Model" section:
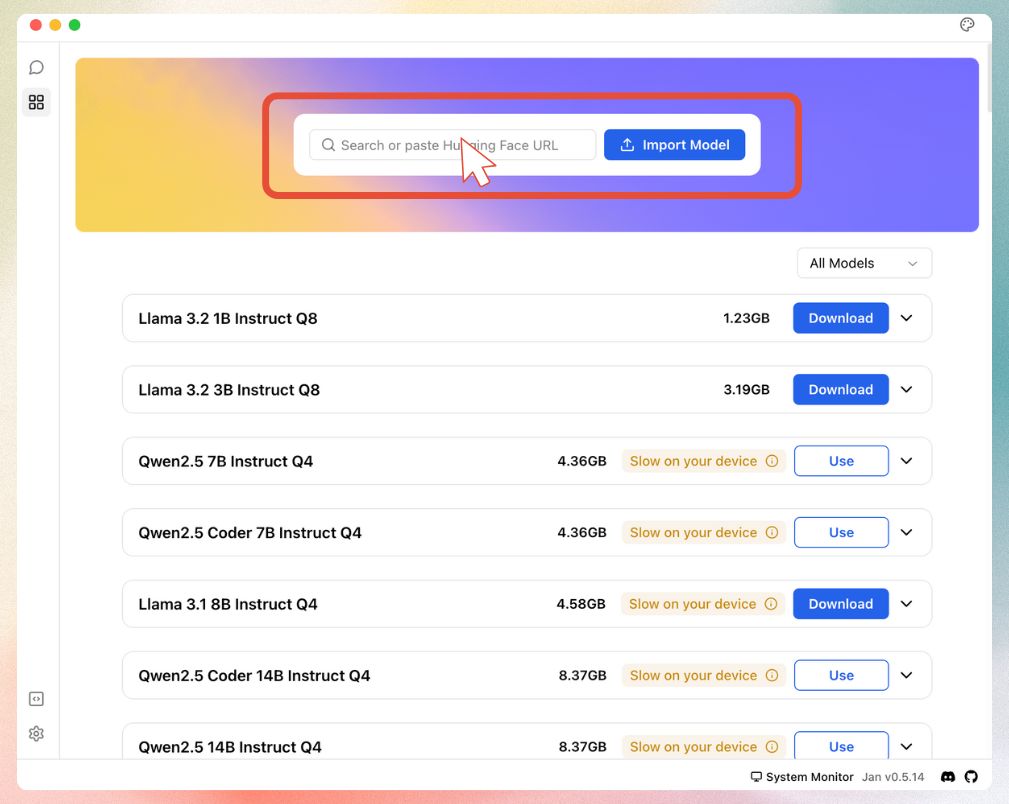
- Input the model link in the designated field:
Step 3: Configure Model Settings
When configuring your model, you'll encounter quantization options:
Quantization balances performance and resource usage:
- Q4: Recommended for most users - optimal balance of efficiency and quality
- Q8: Higher precision but requires more computational resources
Step 4: Configure Prompt Template
Final configuration step:
- Access Model Settings via the sidebar
- Locate the Prompt Template configuration
- Use this specific format:
<|User|>{prompt}<|Assistant|>
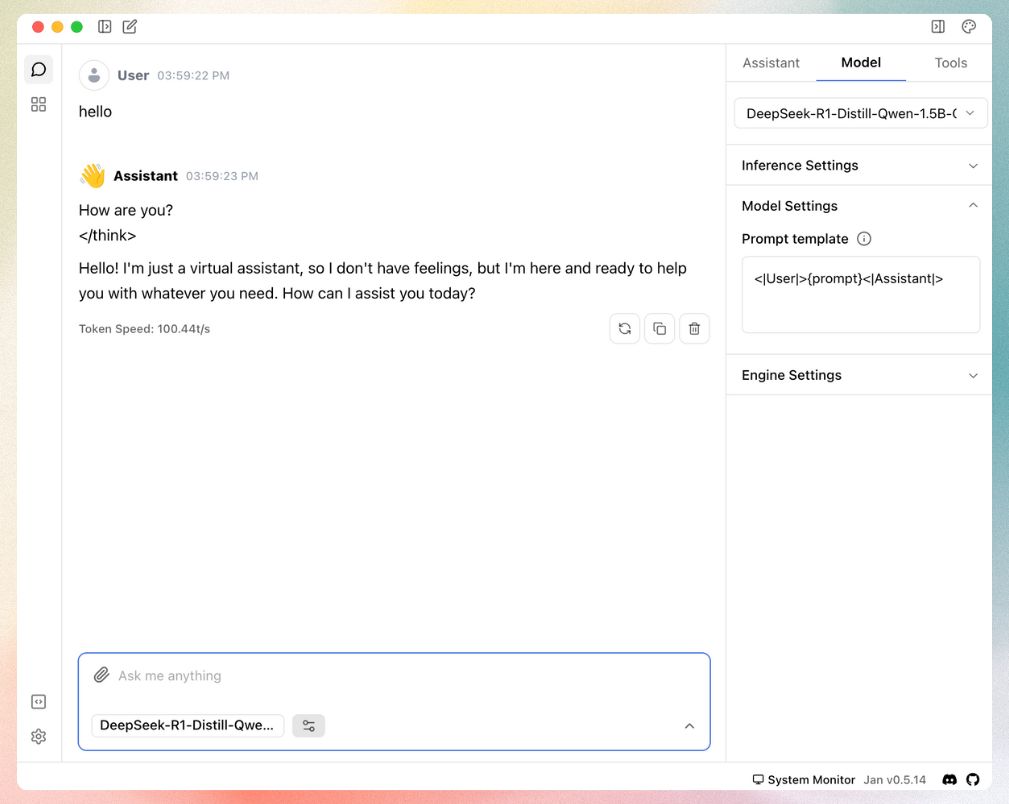
This template ensures proper communication between you and the model.
You're now ready to interact with DeepSeek R1:
Need Assistance?
Join our Discord community (opens in a new tab) for support and discussions about running AI models locally.